
How can we scale up systems for knowledge processes to organizational and social scales? How can technologies provide economies of scale for creation, distribution, and use of knowledge and information?
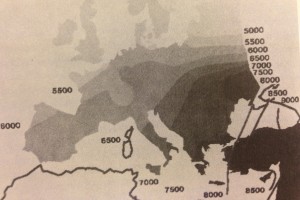 In 1985 I was invited to give a keynote address at the Aerospace Applications of Artificial Intelligence Conference. Could knowledge systems technology drive knowledge processes at scale? What are the bottlenecks and leverage points for creating and distributing knowledge? The paper The Next Knowledge Medium was published in AI Magazine and later in several other places. This paper looks at waves of knowledge creation and spreading at historic scales and reflects on how digital systems and knowledge systems could trigger waves of knowledge creation and distribution today.
In 1985 I was invited to give a keynote address at the Aerospace Applications of Artificial Intelligence Conference. Could knowledge systems technology drive knowledge processes at scale? What are the bottlenecks and leverage points for creating and distributing knowledge? The paper The Next Knowledge Medium was published in AI Magazine and later in several other places. This paper looks at waves of knowledge creation and spreading at historic scales and reflects on how digital systems and knowledge systems could trigger waves of knowledge creation and distribution today.
 The paper was featured on the cover of AI Magazine. It proposed a challenge and offered a cautionary note. To achieve its potential for sharing creating and distributing knowledge at scale, something more was needed beyond the hand-coded construction of knowledge in expert systems:
The paper was featured on the cover of AI Magazine. It proposed a challenge and offered a cautionary note. To achieve its potential for sharing creating and distributing knowledge at scale, something more was needed beyond the hand-coded construction of knowledge in expert systems:
Knowledge engineers are the computer-literate monks of the twentieth century, illuminating their manuscripts in splendid isolation, awaiting perhaps the invention of the next printing press.
To meet their potential, knowledge systems would need to become more like what today we call social networks. In addition, they would have to evolve to support people and computers in synergistic and differentiated roles for producing and distributing knowledge.
 Also in 1989 there was a workshop of prominent leaders in science and information technology to design a program for national collaboratories. I led a committee that sketched needs and technology opportunities. We proposed technological support for knowledge processes for scientific research at a national scale. This led to several national collaboratories and later the digital libraries project.
Also in 1989 there was a workshop of prominent leaders in science and information technology to design a program for national collaboratories. I led a committee that sketched needs and technology opportunities. We proposed technological support for knowledge processes for scientific research at a national scale. This led to several national collaboratories and later the digital libraries project.
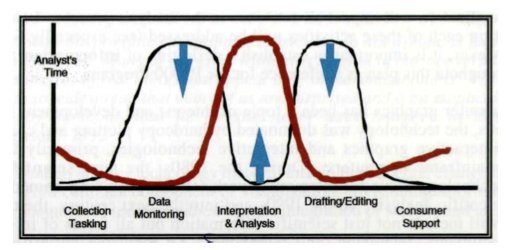 What are the cognitive bottlenecks of knowledge creation by people? Can technology enhance or accelerate it? In 1993, Dan Russell, Peter Pirolli, Stu Card, and I modeled the dynamics of knowledge creation by teams assisted by technology. Our InterCHI paper, The Cost Structure of Sensemaking, addressed these questions and introduced sensemaking to the Computers and Human Interaction (CHI) community.
What are the cognitive bottlenecks of knowledge creation by people? Can technology enhance or accelerate it? In 1993, Dan Russell, Peter Pirolli, Stu Card, and I modeled the dynamics of knowledge creation by teams assisted by technology. Our InterCHI paper, The Cost Structure of Sensemaking, addressed these questions and introduced sensemaking to the Computers and Human Interaction (CHI) community.
In 2002 a PARC team wrote the sensemaking white paper exploring the technical challenges and opportunities for combining human-computer interfaces, natural language technology, and information retrieval technology. This was at the beginning of a wave of commercial investment in systems for knowledge management for the information needs of organizations. After the 911 attacks, we engaged on several sensemaking projects with various intelligence agencies. Sensemaking is now a term of art in business and intelligence analysis.
 In the early 1990’s the internet was becoming the world wide web. This was not seen as good news by everyone. Publishers and other stakeholders were concerned that copyright protection would be ineffective on global digital networks. Would rampant free copying destroy the ability to profit from intellectual products and result in low quality publications? Is it possible to sell content on the web without free copying destroying the market?
In the early 1990’s the internet was becoming the world wide web. This was not seen as good news by everyone. Publishers and other stakeholders were concerned that copyright protection would be ineffective on global digital networks. Would rampant free copying destroy the ability to profit from intellectual products and result in low quality publications? Is it possible to sell content on the web without free copying destroying the market?
I invented a kind of trusted system for securing and distributing content over the web. A 1996 paper Letting Loose the Light explains the concept and its potential use with all sorts of digital works, ranging from books to newspapers to videos, music, and ringtones. This invention resulted in a Xerox/Microsoft spinout and helped launch digital rights management (DRM) technology into the world. In 1997, Scientific American published my paper on Trusted Systems. Using trusted systems for distribution shifts the legal basis of controlling intellectual property from copyright law to contract law. The changing legal basis is explained in Shifting the Possible published in the Berkeley Technology Law Journal and in The Bit and the Pendulum published in The Computer Lawyer.
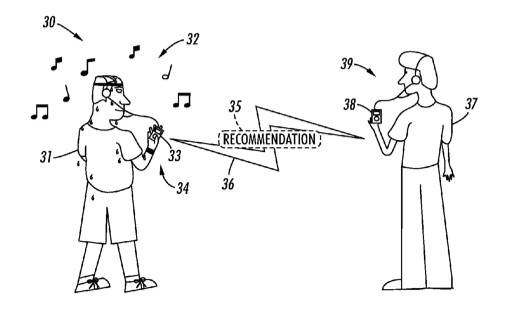 In order to think through a very focused case for distributing information, I did a thought experiment using digital music as a case study — including discovery, recommendation, and purchase. How do we find good music and other works now? Could we simplify finding music in our living environment, making recommendations, and purchasing recommended music? In 2007 I used the occasion of a keynote address at the Digital Rights Strategies conference to describe ways to radically reduce friction in music consumption. This is described in a paper DRM and the Future of Digital Media from that conference and in a later white paper, Social and Personalized: Music Discovery in a Social Medium.
In order to think through a very focused case for distributing information, I did a thought experiment using digital music as a case study — including discovery, recommendation, and purchase. How do we find good music and other works now? Could we simplify finding music in our living environment, making recommendations, and purchasing recommended music? In 2007 I used the occasion of a keynote address at the Digital Rights Strategies conference to describe ways to radically reduce friction in music consumption. This is described in a paper DRM and the Future of Digital Media from that conference and in a later white paper, Social and Personalized: Music Discovery in a Social Medium.
 After developing the concepts for digital music distribution, I wanted to build a system that would do this for more actionable kinds of information. Search engines like Google are great for supporting specific information searches, but they do not work very well for serving my daily information needs. After all, one does not wake up in the morning to do a search about “what’s happening?” I was also dissatisfied with general news publications and by news programs on the radio when I drive home.
After developing the concepts for digital music distribution, I wanted to build a system that would do this for more actionable kinds of information. Search engines like Google are great for supporting specific information searches, but they do not work very well for serving my daily information needs. After all, one does not wake up in the morning to do a search about “what’s happening?” I was also dissatisfied with general news publications and by news programs on the radio when I drive home.
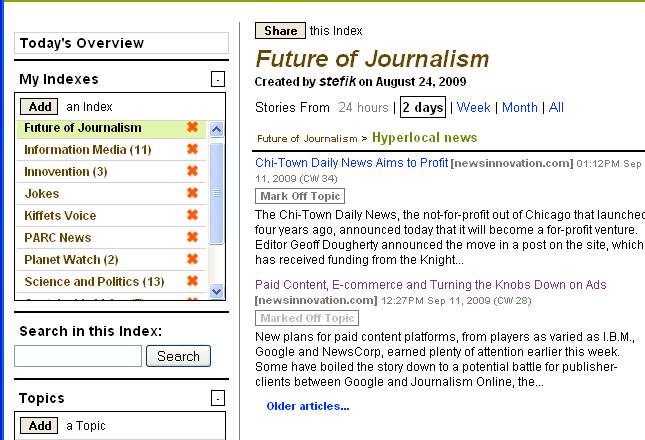
Could computer systems deliver targeted and personalized news? How could systems identify trustworthy sources? Could information be expertly organized? In 2010-2011 Lance Good and I built a social indexing system for delivering personalized news. The system combined human and computer cognition and formalized social roles in the process, distinguishing between publishers of news, curators who organized topical collections, and readers who subscribed to channels and consume news. The core of our approach divided knowledge work between the light work of the many (the readers), the hard work of the few (the curators), and the tireless work of the machines. AI Magazine published our paper The News that Matters to You. It demonstrated a working knowledge medium with publishers, curators, and consumers for thousands of publishers and hundreds of readers.
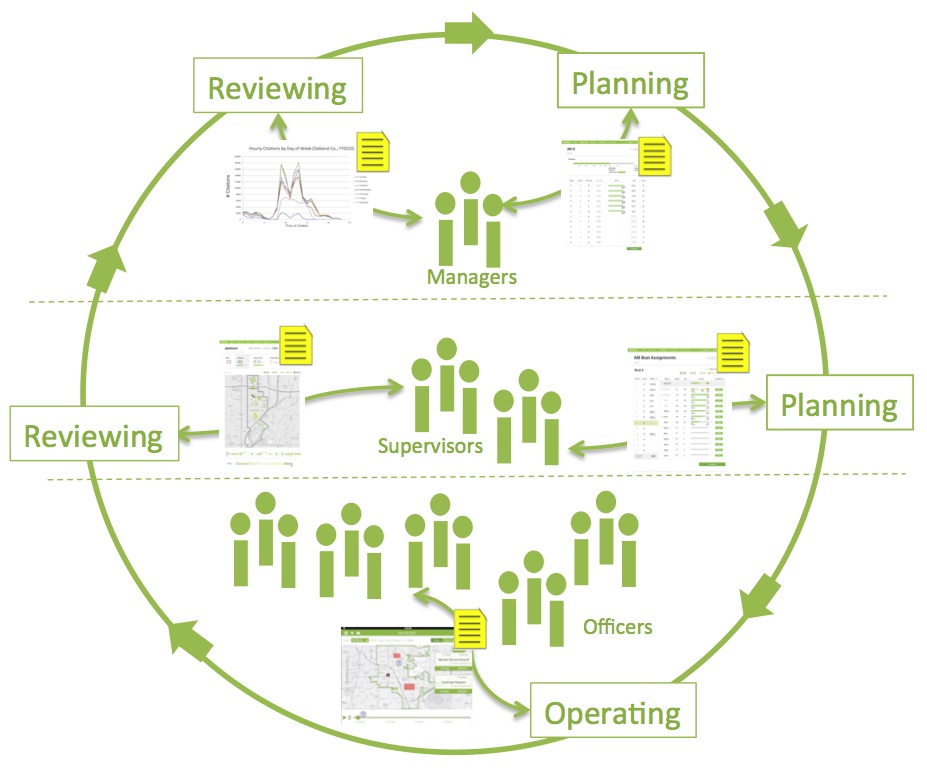 Following the research on social indexing, I returned to the framework of public scale and organizations. How can organizations work effectively? How should they balance competing goals? How can they draw on their diverse members to make better decisions? In the Enforce project with departments of transportation (DOTs) and
Following the research on social indexing, I returned to the framework of public scale and organizations. How can organizations work effectively? How should they balance competing goals? How can they draw on their diverse members to make better decisions? In the Enforce project with departments of transportation (DOTs) and  Departments of Public Works (DPWs) in several cities, we are building systems that combine workflow, analytics and communications (video). The information systems combine human and machine cognition for people in several different organizational roles. Our system, co-designed with its users, is designed to help organizations see what is happening in their environment and to reflect on their own operations in order to understand and optimize their resources and meet organizational goals.
Departments of Public Works (DPWs) in several cities, we are building systems that combine workflow, analytics and communications (video). The information systems combine human and machine cognition for people in several different organizational roles. Our system, co-designed with its users, is designed to help organizations see what is happening in their environment and to reflect on their own operations in order to understand and optimize their resources and meet organizational goals.
Projects: Digital Convergence, Sensemaking, ACH, Digital Rights Management, Social Music, Social Indexing, Enforce, Collaborative Analytics
Books: Internet Dreams, The Internet Edge